![]()
Titanic Visualize Decision Tree
introml.analyticsdojo.com
26. Titanic Classification - Titanic Visualize Decision Tree#
As an example of how to work with both categorical and numerical data, we will perform survival predicition for the passengers of the HMS Titanic.
import os
import pandas as pd
train = pd.read_csv('https://raw.githubusercontent.com/rpi-techfundamentals/spring2019-materials/master/input/train.csv')
test = pd.read_csv('https://raw.githubusercontent.com/rpi-techfundamentals/spring2019-materials/master/input/test.csv')
print(train.columns, test.columns)
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object') Index(['PassengerId', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
Here is a broad description of the keys and what they mean:
pclass Passenger Class
(1 = 1st; 2 = 2nd; 3 = 3rd)
survival Survival
(0 = No; 1 = Yes)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare
cabin Cabin
embarked Port of Embarkation
(C = Cherbourg; Q = Queenstown; S = Southampton)
boat Lifeboat
body Body Identification Number
home.dest Home/Destination
In general, it looks like name, sex, cabin, embarked, boat, body, and homedest may be candidates for categorical features, while the rest appear to be numerical features. We can also look at the first couple of rows in the dataset to get a better understanding:
train.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
26.1. Preprocessing function#
We want to create a preprocessing function that can address transformation of our train and test set.
from sklearn.impute import SimpleImputer
import numpy as np
cat_features = ['Pclass', 'Sex', 'Embarked']
num_features = [ 'Age', 'SibSp', 'Parch', 'Fare' ]
def preprocess(df, num_features, cat_features, dv):
features = cat_features + num_features
if dv in df.columns:
y = df[dv]
else:
y=None
#Address missing variables
print("Total missing values before processing:", df[features].isna().sum().sum() )
imp_mode = SimpleImputer(missing_values=np.nan, strategy='most_frequent')
df[cat_features]=imp_mode.fit_transform(df[cat_features] )
imp_mean = SimpleImputer(missing_values=np.nan, strategy='mean')
df[num_features]=imp_mean.fit_transform(df[num_features])
print("Total missing values after processing:", df[features].isna().sum().sum() )
X = pd.get_dummies(df[features], columns=cat_features, drop_first=True)
return y,X
y, X = preprocess(train, num_features, cat_features, 'Survived')
test_y, test_X = preprocess(test, num_features, cat_features, 'Survived')
Total missing values before processing: 179
Total missing values after processing: 0
Total missing values before processing: 87
Total missing values after processing: 0
26.2. Train Test Split#
Now we are ready to model. We are going to separate our Kaggle given data into a “Train” and a “Validation” set.
#Import Module
from sklearn.model_selection import train_test_split
train_X, val_X, train_y, val_y = train_test_split(X, y, train_size=0.7, test_size=0.3, random_state=122,stratify=y)
print(train_y.mean(), val_y.mean())
0.38362760834670945 0.3843283582089552
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn import metrics
from sklearn import tree
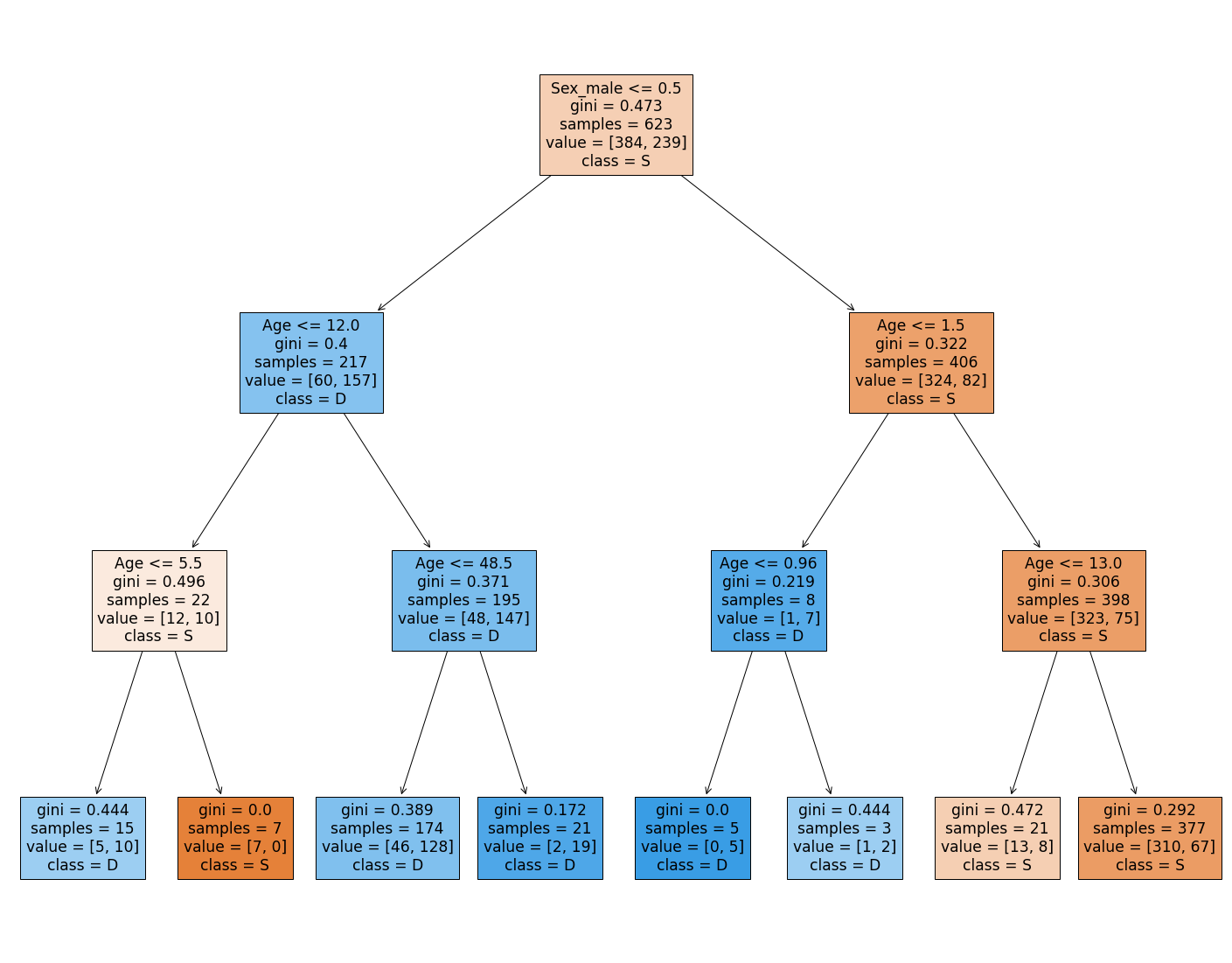
classifier = tree.DecisionTreeClassifier(max_depth=3)
#This fits the model object to the data.
classifier.fit(train_X[['Age','Sex_male']], train_y)
#This creates the prediction.
train_y_pred = classifier.predict(train_X[['Age','Sex_male']])
val_y_pred = classifier.predict(val_X[['Age','Sex_male']])
test['Survived'] = classifier.predict(test_X[['Age','Sex_male']])
print("Metrics score train: ", metrics.accuracy_score(train_y, train_y_pred) )
print("Metrics score validation: ", metrics.accuracy_score(val_y, val_y_pred) )
Metrics score train: 0.7929373996789727
Metrics score validation: 0.8134328358208955
from sklearn import tree
text_representation = tree.export_text(classifier)
print(text_representation)
|--- feature_1 <= 0.50
| |--- feature_0 <= 12.00
| | |--- feature_0 <= 5.50
| | | |--- class: 1
| | |--- feature_0 > 5.50
| | | |--- class: 0
| |--- feature_0 > 12.00
| | |--- feature_0 <= 48.50
| | | |--- class: 1
| | |--- feature_0 > 48.50
| | | |--- class: 1
|--- feature_1 > 0.50
| |--- feature_0 <= 1.50
| | |--- feature_0 <= 0.96
| | | |--- class: 1
| | |--- feature_0 > 0.96
| | | |--- class: 1
| |--- feature_0 > 1.50
| | |--- feature_0 <= 13.00
| | | |--- class: 0
| | |--- feature_0 > 13.00
| | | |--- class: 0
with open("decistion_tree.log", "w") as fout:
fout.write(text_representation)
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(25,20))
_ = tree.plot_tree(classifier,
feature_names=['Age','Sex_male'],
class_names='SD',filled=True)
!pip install dtreeviz
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting dtreeviz
Downloading dtreeviz-1.3.7.tar.gz (62 kB)
|████████████████████████████████| 62 kB 809 kB/s
?25hRequirement already satisfied: graphviz>=0.9 in /usr/local/lib/python3.7/dist-packages (from dtreeviz) (0.10.1)
Requirement already satisfied: pandas in /usr/local/lib/python3.7/dist-packages (from dtreeviz) (1.3.5)
Requirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from dtreeviz) (1.21.6)
Requirement already satisfied: scikit-learn in /usr/local/lib/python3.7/dist-packages (from dtreeviz) (1.0.2)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.7/dist-packages (from dtreeviz) (3.2.2)
Collecting colour
Downloading colour-0.1.5-py2.py3-none-any.whl (23 kB)
Requirement already satisfied: pytest in /usr/local/lib/python3.7/dist-packages (from dtreeviz) (3.6.4)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib->dtreeviz) (0.11.0)
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->dtreeviz) (2.8.2)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->dtreeviz) (1.4.4)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib->dtreeviz) (3.0.9)
Requirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from kiwisolver>=1.0.1->matplotlib->dtreeviz) (4.1.1)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.1->matplotlib->dtreeviz) (1.15.0)
Requirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas->dtreeviz) (2022.2.1)
Requirement already satisfied: atomicwrites>=1.0 in /usr/local/lib/python3.7/dist-packages (from pytest->dtreeviz) (1.4.1)
Requirement already satisfied: more-itertools>=4.0.0 in /usr/local/lib/python3.7/dist-packages (from pytest->dtreeviz) (8.14.0)
Requirement already satisfied: pluggy<0.8,>=0.5 in /usr/local/lib/python3.7/dist-packages (from pytest->dtreeviz) (0.7.1)
Requirement already satisfied: py>=1.5.0 in /usr/local/lib/python3.7/dist-packages (from pytest->dtreeviz) (1.11.0)
Requirement already satisfied: setuptools in /usr/local/lib/python3.7/dist-packages (from pytest->dtreeviz) (57.4.0)
Requirement already satisfied: attrs>=17.4.0 in /usr/local/lib/python3.7/dist-packages (from pytest->dtreeviz) (22.1.0)
Requirement already satisfied: scipy>=1.1.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn->dtreeviz) (1.7.3)
Requirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit-learn->dtreeviz) (1.1.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from scikit-learn->dtreeviz) (3.1.0)
Building wheels for collected packages: dtreeviz
Building wheel for dtreeviz (setup.py) ... ?25l?25hdone
Created wheel for dtreeviz: filename=dtreeviz-1.3.7-py3-none-any.whl size=68151 sha256=4d335a7a96a8af423e490f1dae94a65b9f6647aa29d3079b9d2328928f36c570
Stored in directory: /root/.cache/pip/wheels/bf/ba/9f/87c689d8d3c2916793f2dccc57d3dc3b283e0ccf8cb4ca4cad
Successfully built dtreeviz
Installing collected packages: colour, dtreeviz
Successfully installed colour-0.1.5 dtreeviz-1.3.7
from dtreeviz.trees import dtreeviz # remember to load the package
viz = dtreeviz(classifier, train_X[['Age','Sex_male']], y,
target_name="Survived",
feature_names=['Age','Sex_male'],
class_names=list('SD'))
viz
/usr/local/lib/python3.7/dist-packages/sklearn/base.py:451: UserWarning: X does not have valid feature names, but DecisionTreeClassifier was fitted with feature names
"X does not have valid feature names, but"
/usr/local/lib/python3.7/dist-packages/numpy/core/fromnumeric.py:3208: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
return asarray(a).size
/usr/local/lib/python3.7/dist-packages/matplotlib/cbook/__init__.py:1376: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
X = np.atleast_1d(X.T if isinstance(X, np.ndarray) else np.asarray(X))
WARNING:matplotlib.font_manager:findfont: Font family ['Arial'] not found. Falling back to DejaVu Sans.
WARNING:matplotlib.font_manager:findfont: Font family ['Arial'] not found. Falling back to DejaVu Sans.
WARNING:matplotlib.font_manager:findfont: Font family ['Arial'] not found. Falling back to DejaVu Sans.
